If you want to just see an explanation of the issue, you can skip to THE TECHNICAL ISSUE, below. First, I get to rant a bit and give some context.
When I first returned to blogging after eight years, it was not with a traditional blog: it was with The Doug Alone PROLOGUE. It was a place for me to post notes and recaps about the solo rpg stuff I was doing.1 Only there was a problem. I actually mentioned it on my final post on that blog. Google more or less refused to index it.
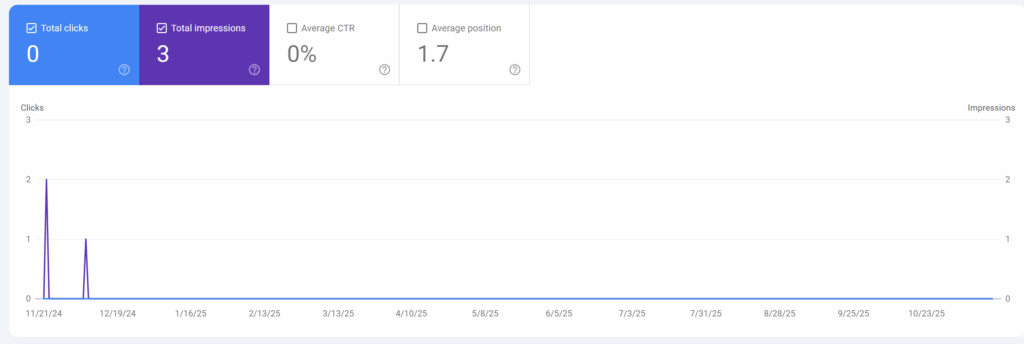
It looks like it did at least briefly index a single page and then wiped it later.
Even though the blog was primarily meant as a play journal, there were elements that I wanted people to find. Only there was a primary error that kept showing up by way of explanation:
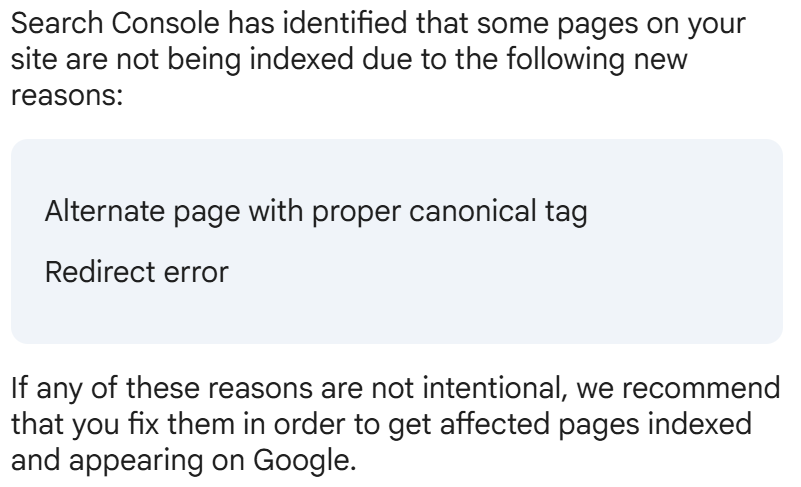
I had a vague notion of what that meant but the more I looked into it, the more I found posts by people insisting it was not an error. It was intended. It’s not up to Google to SEO for you. Maybe your blog isn’t worthy. Here’s a reddit thread with most of those things said from just a few months ago.
However, after Noism Games posted a post noting their Blogger/Blogspot traffic had just plummeted, I felt curious and looked again.
Doug Is Right: The Blogger Canonical Edition
Here’s the tl;dr: I am right. The SEO experts are wrong on this one. Neener neener.

I knew I was roughly correct. I’ve worked with a lot of different web platforms over the years and am well aware that Google is a fickle beast when it comes to promoting something (say, a one-off post about carpet beetles) over things that are more core to your blog identity (such as old posts about a variety of horror movies). However, months of Google flat out ignoring a blog with unique content was not consistent. At least a few pages would have passed The Algorithm.
Those more in the know of the technical issues probably know, and I had an idea but just not why Blogger/Blogspot was being hit by it. Had I cared more, I would probably have put it together earlier. Would I have still moved blogs? Oh yes. I like having my own space to play.
The Technical Issue
What’s the issue?
Webpages can have canonical tags. It’s not required. It just helps Google (and other search engine type things) to say that the page with the listing is the page you want to index. If you are on a platform where your content might bounce from page to page, you can use it to say that this is the correct page.
EXAMPLE: You have a cooking blog. You have a set of pages with different recipes and other pages that include snippets of those recipes and you don’t want Google to send folks to the pages with only the snippets (such as a category page or a front page that shows the most recent). You prefer your recipes to be front and center. You put the canonical tag on those pages.
In the specific case of Blogger/Blogspot, there’s a bit of code that basically tells each new page to have a tag on the post itself:
<b:include data='blog' name='all-head-content'/>One aspect of this is to drop a simple line that gives the URL and says “this one, Google” in the <HEAD>:
<link href='https://dougalone.blogspot.com/2025/09/beginning-to-migrate-some-content-to.html' rel='canonical'/>And that should be well in good except for a technical glitch on Google’s side. It does not scan the blog like a person on a home computer will. It scans largely as a mobile device. And Blogger/Blogspot, a GOOGLE PRODUCT, tries to be helpful by serving up a ?m=1 version of the page. Old themes did not have a native mobile version. Newer ones do, but the artifact from Ye Olde Times is still there.
Which means that Google gets a link like this for the page linked above:
https://dougalone.blogspot.com/2025/09/beginning-to-migrate-some-content-to.html?m=1
You can likely see where this is going. If you click on it, it is identical to the previous page, except the rel='canonical' is not pointing to that link, it is posted to the .html, not the .html?m=1 version.
This means for every Blogger/Blogspot page scanned, Google sees a page constantly serving up alternate pages and because the ?m=1 keeps persisting, it constantly fails to find the canonical pages.
What’s the Fix?
Unfortunately, the two primary fixes are both on Google engineers and since this has been brewing for a few years, I have no idea if they will fix it. Hopefully so, because Blogger/Blogspot is a nice all-in-one blog for people who don’t want to fiddle too hard and just want to get their content out there.
FIX #1 would be for Google to not treat ?x=y as wholly different pages at least in the case of mobile pages where the canonical link has identical content. I appreciate there are lots of cases where it is different content, but there should be a way to prevent that.
FIX #2 would be for Blogger/Blogspot to stop appending the ?m=1 to mobile pages. There are better ways to handle that. That feels like an artifact from 2010 era internet. Back when you had completely separate mobile sites. Ah, I remember those days unfondly.
What can we do as users of the product? I’m not sure. If you look, there are suggestions for Javascript workarounds. I am attempting to use the script at this page. Go gently into that night and double check before you use it, yourself.
I also did try updating my robots.txt file to tell Google to ignore ?m=1 pages. Will it work? I don’t know. I’m not precisely holding my breath. If I remember to check in a couple of months and it has worked, I’ll let you know.
User-agent: Mediapartners-Google
Disallow:
User-agent: *
Disallow: /search
Disallow: /share-widget
Disallow: /*?m=1
Allow: /
Sitemap: https://dougalone.blogspot.com/sitemap.xmlObviously, if you want to use that you want to change the final line to be whatever your blog’s address is. I’ve seen variations of that across multiple posts so I don’t know where it originated. Apparently older Blogger blogs had a baked in robots.txt but mine didn’t. I had to add it whole cloth.
Let’s see what the outcome of this double approach might be.
NOTE: It is possible that Google will eventually scan it via a non-mobile-first scanner and make all this a non-issue. Just 16-months seems like a fair time to run a test.
- There is a paradox of solo play where a lot of folks, myself included, have a strong urge to share it with someone. The initial idea was not a blog. I thought about streaming some stuff on Youtube. Since I ended up figuring out a lot of mistakes, tweaking a lot of notions, and so forth: I am glad I went for a format that did not involve me just sitting there confused and sweaty on camera. ↩︎