I don’t know who in their right mind thought it was a good idea to let me have so many green-tea-and-gins last night but they were a complete idiot.
Name probably rhymes with bug or rug or something similar.
Funnily, it wasn’t the gin that was the real problem. Had I mixed 2-3 shots of gin with a liter of water and drank that I’d probably feel pretty swell today. It was the couple of liters of green tea that kept me up to something like 03:00.
One year I’m just going to go to bed for New Year’s. Since Belgian parties are just getting started at midnight, it probably won’t be for a couple of years, mind.

It’s a gray day in Grimbergen which is just sort of saying, “It’s a day.” Kind of nice, though. Not too cold. Not too loud. Windy in a pleasant way. Noon but feels either earlier or later. A kind of liminal space.
I’m sitting here next to two open windows letting in 5C air and giving a thought to the standard thought that we all do on 1 Jan: resolutions. I swore off the whole thing a few years back, mostly, but sometimes they are fun. Sometimes they are hopeful.
Over on the Doug Alone, I talked about (mostly) leaving crowdfunding. That’s one of them. We’ll see how that goes.
A couple of other bigger ones in a more general sense of things (since crowdfunding is pretty much 100% tied into my solo roleplaying hobby) are (a) reducing gamification in my life and (b) generally increasing privacy awareness. And (a) is going to impact a lot of other potential resolutions.
“It’s Going to Be Our Year!”
Before I get to that, let me give you some insight into the core Doug experience. Last night, after getting the first green-tea-and-gin in myself, I started sending out pre-Happy-New-Year’s messages to a few friends and while the messages tended to be personalized, in very nearly all of them I joked about the phrase, “This is going to be our year!” Those who get my sense of humor appreciated I was both making fun of arbitrary goalposts and whispering the foulest curse of them all: hope.
It helps you have say it with a shaky voice like a person saying, “Maybe the cave troll isn’t home, we should go into the dark cave and find out.”
Joyfully nihilistic curses aside, maybe it will be. I don’t know. I just take things as they come, mostly.
(a) Reducing Gamification
This is frankly the biggest one for mental health and general well-being. I have no specific numbers (which feels like a pun) but the gamification of every single aspect of our life feels like it is increasing. Earn points for purchases. Day-week-month streaks in every app. Add five friends to earn a point. Allow GenAI to access your data? Well, we’ll do it anyhow but if you give it away you can get a badge to show off on your profile that no one will ever click.
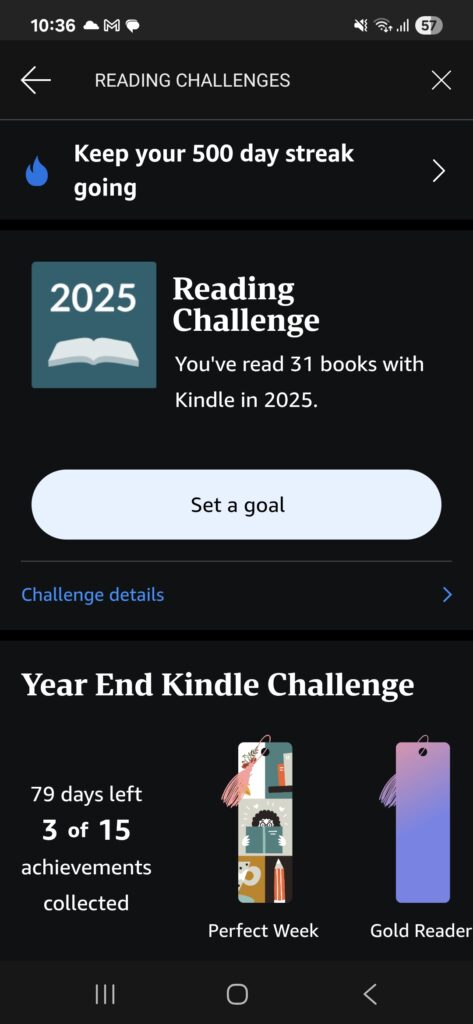
I pay money to upgrade the “freemium” experience of Duolingo, Geoguessr, and NYTimes Games. All three are big about pushing daily plays and uses [“Please stay addicted to our services”]. Badges. Achievements. I “buy” (lease? not sure what the proper legal term would be) books on the Kindle and it sends me notifications about not letting my streak expire. When I started deleting social media, I was seeing it more, there. Stuff that has no business setting weekly/monthly/annual goals have started bundling it.
Back 20 projects on Crowdfundr.ai? You get platinum status. There are no benefits but still we love you like your parents never did. Spend $2000 on gachas? You get 1.25 points per $100 spent instead of just 1 point.
It’s an incessant noise. And the fact that so rarely do hitting any of these milestones unlock anything besides maybe meaningless in-game currency shows how effective it is to just offer up a hexagonal png to keep people reaching for a goal that only exists to increase company profits through addictive behavioral programing.
When I was first workshopping this resolution, I thought about flat out cutting out any app or system that had such systems baked in only I realized, relatively quickly, that I would more or less be able to not access the things I actually use.
Instead, the idea is to simply ignore the badges, achievements, streaks, and other stupid bullshit designed to increase addiction. If I didn’t read today, no more panic reading a chapter to keep my Kindle streak going. If I don’t feel like doing Duolingo, just let the streak die. In some cases, this will likely be tied into getting rid of some freemium upgrades. So it goes.
The irony of this is that it kind of negates the concept of resolutions. I do want to read more. Play more of my old favorite games. I want to solo play more. Take bigger risks. Lose weight. Work on fixing my ankle.
I will likely have to compromise to some degree. It can be hard to lose weight without tracking calories somewhat. It can be hard to budget better without a budget.
Just absolutely no apps to do the data for me.
(b) Increasing Privacy
Which brings us to the other major resolution. Find ways to increase my overall privacy. This one is harder to specify without sounding a bit like a conspiracy nut. Or, perhaps, it is easier to specify:
- Stop giving private information to unlock upgrades,
- Use more offline stuff and fewer things that require third party tracking,
- Avoid using cloud-based systems more, especially now that so many cloud-based systems have decided that using them is akin to giving your personal documents to their AI systems,
- Using my own storage back-up solutions, own media servers, own email servers, etc.
- Using more encryption that isn’t designed to expose the data to the host,
- etc
There are so many little ways this one will show up. It makes me think of something that Northerlion (the Twitch Streamer) said. He mentioned that getting cash from the ATM feels like a borderline criminal act because you get the cash and then no one really tracks how you spend it. The sense that if we just use the stuff we own, we are going dark.
After the move to Belgium, I have been watching more stuff streaming from my personal server and through physical media, partially because I would have to use VPN to watch my American-media-libraries despite paying a lot of real money to build them up and still being an American citizen.
And one of the aspects of this is that when I put in that DVD/Blu-Ray/CD then no one but myself really knows what I am watching or playing. If I play a CD a dozen times, it doesn’t get tracked and used to sell me something. I can watch a movie a dozen times and it is up to me to watch trailers to see what else I might like.
We’ve been so conditioned to accept The Algorithm(TM)’s “help” to fill every waking hour with media that we are giving up the ability to own these pieces of happiness. It is becoming increasingly obvious how much companies don’t want us to own our own media now that I kind of have to own it to enjoy the things I enjoy.
Just look at videogames. Now you buy a code in a physical case and you attach that code to your account and if that library every goes away, you bought a physical case in a store to temporarily lease a game.
Or movies where you buy a blu-ray and they want you to use the “free digital copy” code so they can keep better track of who has what. Some Blu-rays and DVDs have features that require you to access the internet to see fully.
“If you are not paying for it, you are not the customer,” is a lie. You are the customer, always, but also the product. It’s kind of up to us to set the line and we are currently losing and pretending its inevitable.
And that’s…madness.